Introduction

Cet article est le troisième sur quatre prévus présentant un livre très récent dédié au Big Data, à la Data Science et notamment au Machine Learning.
Ce troisième article donnera ma vision du livre d'un point de vue du Data Mining.
On parlera essentiellement ici des :
(paramétrique et non, supervisé ou non, probabiliste ou non...)
Concernant les techniques de réduction de dimension, il est dommage qu'elles n'apparaissent pas en chapitre 6 car c'est souvent un préalable en data mining.
Un statisticien apprécierait également que les notions plus mathématiques que sont les critères AIC et BIC soient abordées ne seraient-ce qu'en bas de page.
Il est juste dommage de ne pas avoir évoquer le sujet tant des outils comme WATSON d'IBM commence à prendre de plus en plus d'importance dans l'analyse du langage naturel.
D'ailleurs, les outils de "NLP" (Natural Language Processing) utilisent du Machine Learning pour déterminer à quel groupe grammatical appartiennent tel ou tel élément d'une phrase.
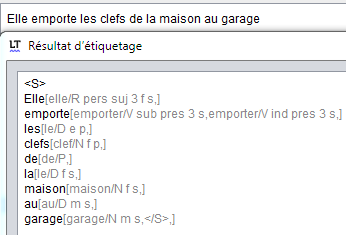
Voici un exemple de reconstruction de l'arbre grammatical à partir d'un parseur NLP (ici LanguageTool):
Le livre permet d'avoir tous les concepts théoriques pour faire du Machine Learning, il est évident qu'un livre de 220 pages ne peut pas tout couvrir mais l'essentiel y est.
Comme souvent, le Data Scientist en herbe devra compléter ses connaissances d'algo notamment sur les réseaux de neurones car, même s'ils n'ont plus la côte, ils n'ont même pas été abordés dans l'ouvrage ainsi que tout ce qui concerne les mélanges de gaussiennes.
L'ouvrage a été l'occasion pour moi de découvrir les forêts aléatoires comme algo pouvant être performant. Ne croyant que ce que je teste, je validerais (ou pas) l'affirmation du livre sur la performance supérieure de cette famille d'algo sur les SVMs lors d'un prochain article.
On parlera essentiellement ici des :
- chapitre 6 : Exploration et préparation des données
- chapitre 7 : Machine Learning
Encore une fois, le livre est une excellente introduction à ce sujet complexe qu'est l'apprentissage artificiel (Machine Learning).
Que peut retenir un spécialiste du Data Mining du livre ?
Sur le chapitre 6 : Exploration et préparation des données
- Sur cet aspect, l'essentiel est dans le livre présentant la diversité des types de données et des moyens de les explorer et de les préparer.
- Cependant, le chapitre de 16 pages consacrés à ce sujet est sous-dimensionné par rapport à l'importance d'avoir de bonnes données en entrée. Mes profs en Data Mining nous martelaient bien le message suivant : l'analyse et pré-traitement des données représentent au moins 80% du travail en Machine Learning (=> cette notion n'apparaît pas dans le livre).
- En exploration des données, il est étonnant de ne pas déjà parler de classifications automatisées pour se donner une idée des regroupements dans les données (la notion de kmeans est abordée en chapitre 7).
- Il aurait été intéressant d'évoquer (ne serait-ce qu'en note de bas de page) les méthodes pour les fonctions de densité comme les fenêtres de Parzen qui sont une généralisation des histogrammes. (Ceci est présenté en chapitre 8 dans le livre dans la partie visualisation).
Sur le chapitre 7 : Machine Learning
- Voici le détail des algorithmes abordés:
(paramétrique et non, supervisé ou non, probabiliste ou non...)
- régression linéaire
- k plus proches voisins
- classification naïve bayésienne
- régression logistique
- k-moyenne (ou k-means)
- arbre de décision
- forêt aléatoires
- machine à vecteur support SVM
- Des techniques de réduction dimensionnelle (dont l'ACP)
- Ce que j'aime bien :
- une description théorique et accessible à tous
- les avantages de l'algorithme
- ses inconvénients
Hum... C'est tout? Y a pas d'autres algorithmes ?
Encore une fois, le livre ne fait que 220 pages ce qui est bien insuffisant pour devenir, malgré la phrase choc du livre, un "manuel du Data Scientist".
Là, le chapitre 7 m'a clairement laissé sur ma faim, le titre n'est-il pas "Big Data et Machine Learning" ? Dans "Learning" il y a apprentissage, la notion est abordée mais vraiment survolée. J'y reviendrais dans un article dédié à l'apprentissage articifiel.
Coté algorithme, aucune référence aux réseaux de neurones n'est faite ! C'est pourtant le classificateur universel de base en Data Mining.
 |
| Schéma interne d'un réseau de neurones (source Wikimédia CC3) |
{kind=link}
Sans les réseaux de neurones, il manque toute une famille d'algorithme :
- Le perception multi-couche (MLP en anglais) qui sert universellement en classification, en régression et prévision. Il est certes plus dur à expliquer aux néophytes mais le livre a réussi l'exploit d'expliquer les SVM de manière claire. Le problème des MLP est la mise en place de l'architecture du réseau de neurone et de son côté "boite noire" par la suite.
- Les réseaux de neurones temporels (ex: TDNN)
- Les chaînes de Markov cachée (HMM en anglais) pourtant très utilisées en prévision pour la reconnaissance vocale et gestuelle
- Il manque des références à la famille autour des K-moyennes : K-medoids, la classification ascendante hiérarchique (appelé CAH) permettant de construire un dendogramme.
- Les cartes auto-organisatrices (de Kohonen) qui sont une amélioration des k-means qui permettent de classifier des données en tenant compte des notions de voisinages et plus globalement de la topologie du couple donnée/réseau de neurone.
- Bien que l'on parle du k-means, le livre n'évoque pourtant pas l'algorithme EM (Expectation-Maximisation) pour trouver les mélanges de gaussiennes (dit aussi GMM).
De plus, sur certains algorithmes présentés, d'autres précisions auraient été utiles. Par exemple, c'est pour les SVM, où il n'a pas été mentionné en avantage qu'avec très peu de données, l'algo est performant. En autre car celui-ci s'intéresse aux frontières entre données à classifier (contrairement aux MLP et autre algo de stats).
Autre oubli, celui de la logique Floue. Tous les algos présentés dans le livre donnent l'impression de trouver une valeur numérique ou catégorielle unique. Or, il existe des variantes pour avoir des prévisions non pas "binaire" 0 ou 100% (oui/non) mais proposant des probas de réalisation (ex: 60%) d'une catégorie et 40% d'une autre. Cela rejoint aussi les algos de type mélange de gaussienne comme l'EM.
Concernant les techniques de réduction de dimension, il est dommage qu'elles n'apparaissent pas en chapitre 6 car c'est souvent un préalable en data mining.
Sur la comparaison entre modèles :
La validation croisée est expliquée par un schéma bien parlant, de même pour les courbes ROC et on a bien la notion de matrice de confusion, tout y est. Tout ceci est par contre découpé bizarrement entre le chapitre 7 et le 8.Un statisticien apprécierait également que les notions plus mathématiques que sont les critères AIC et BIC soient abordées ne seraient-ce qu'en bas de page.
Et le Text Mining dans tout ça ?
Bien qu'une "analyse" de texte soit évoquée lors de la présentation d'Hadoop (Comptage de mots), une personne cherchant des entrées pour du Text Mining restera sur sa faim.Il est juste dommage de ne pas avoir évoquer le sujet tant des outils comme WATSON d'IBM commence à prendre de plus en plus d'importance dans l'analyse du langage naturel.
D'ailleurs, les outils de "NLP" (Natural Language Processing) utilisent du Machine Learning pour déterminer à quel groupe grammatical appartiennent tel ou tel élément d'une phrase.
Voici un exemple de reconstruction de l'arbre grammatical à partir d'un parseur NLP (ici LanguageTool):
Pour conclure
Le livre permet d'avoir tous les concepts théoriques pour faire du Machine Learning, il est évident qu'un livre de 220 pages ne peut pas tout couvrir mais l'essentiel y est.
Comme souvent, le Data Scientist en herbe devra compléter ses connaissances d'algo notamment sur les réseaux de neurones car, même s'ils n'ont plus la côte, ils n'ont même pas été abordés dans l'ouvrage ainsi que tout ce qui concerne les mélanges de gaussiennes.
L'ouvrage a été l'occasion pour moi de découvrir les forêts aléatoires comme algo pouvant être performant. Ne croyant que ce que je teste, je validerais (ou pas) l'affirmation du livre sur la performance supérieure de cette famille d'algo sur les SVMs lors d'un prochain article.
Aucun commentaire:
Enregistrer un commentaire